publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2025
-
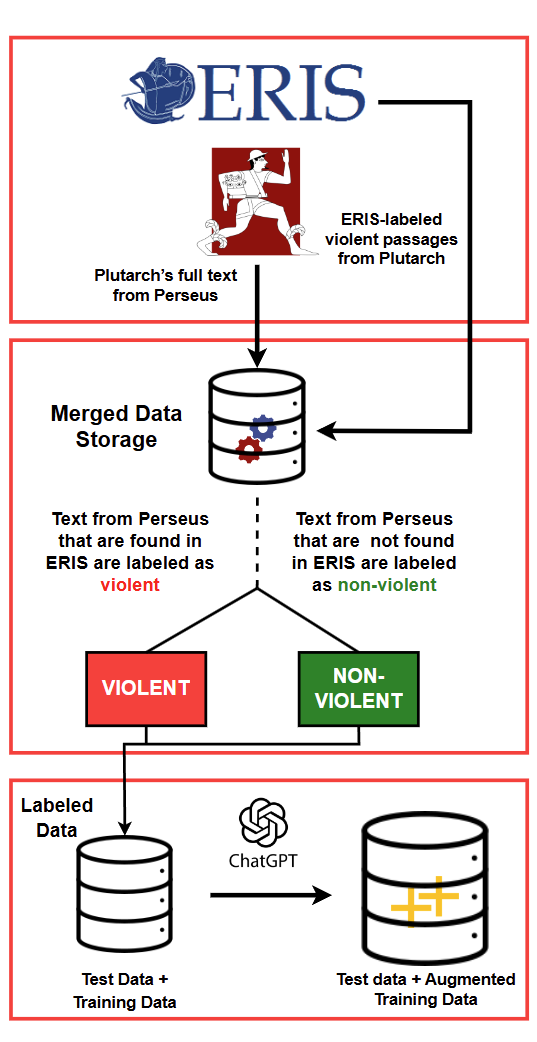 Automating Violence Detection and Categorization from Ancient TextsAlhassan Abdelhalim and Michaela RegneriIn Proceedings of the 9th Joint SIGHUM Workshop on Computational Linguistics for Cultural Heritage, Social Sciences, Humanities and Literature (LaTeCH-CLfL 2025), May 2025
Automating Violence Detection and Categorization from Ancient TextsAlhassan Abdelhalim and Michaela RegneriIn Proceedings of the 9th Joint SIGHUM Workshop on Computational Linguistics for Cultural Heritage, Social Sciences, Humanities and Literature (LaTeCH-CLfL 2025), May 2025Violence descriptions in literature offer valuable insights for a wide range of research in the humanities. For historians, depictions of violence are of special interest for analyzing the societal dynamics surrounding large wars and individual conflicts of influential people. Harvesting data for violence research manually is laborious and time-consuming. This study is the first one to evaluate the effectiveness of large language models (LLMs) in identifying violence in ancient texts and categorizing it across multiple dimensions. Our experiments identify LLMs as a valuable tool to scale up the accurate analysis of historical texts and show the effect of fine-tuning and data augmentation, yielding an F1-score of up to 0.93 for violence detection and 0.86 for fine-grained violence categorization.
@inproceedings{abdelhalim-regneri-2025-automating, title = {Automating Violence Detection and Categorization from Ancient Texts}, author = {Abdelhalim, Alhassan and Regneri, Michaela}, editor = {Kazantseva, Anna and Szpakowicz, Stan and Degaetano-Ortlieb, Stefania and Bizzoni, Yuri and Pagel, Janis}, booktitle = {Proceedings of the 9th Joint SIGHUM Workshop on Computational Linguistics for Cultural Heritage, Social Sciences, Humanities and Literature (LaTeCH-CLfL 2025)}, month = may, year = {2025}, address = {Albuquerque, New Mexico}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2025.latechclfl-1.7/}, doi = {10.18653/v1/2025.latechclfl-1.7}, pages = {64--78}, isbn = {979-8-89176-241-1}, } -
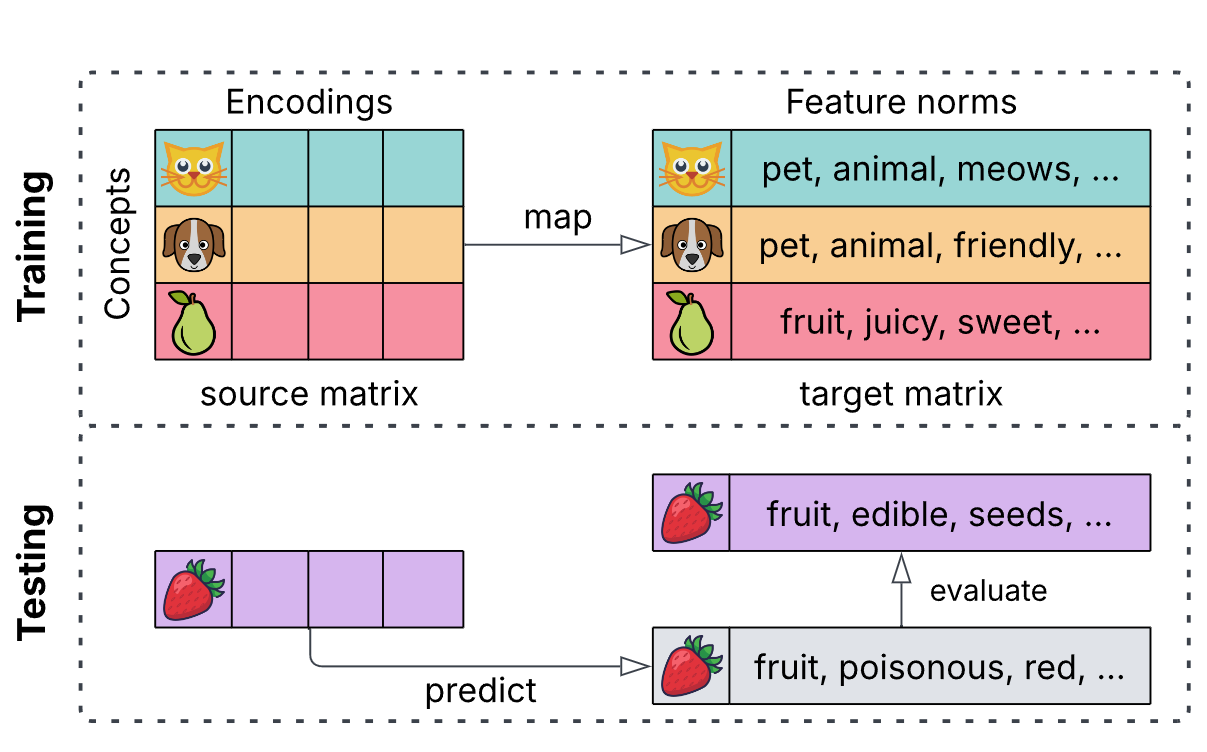 Prediction is not Explanation: Revisiting the Explanatory Capacity of Mapping EmbeddingsHanna Herasimchyk, Alhassan Abdelhalim, Sören Laue, and 1 more authorarXiv preprint arXiv:2508.13729, May 2025
Prediction is not Explanation: Revisiting the Explanatory Capacity of Mapping EmbeddingsHanna Herasimchyk, Alhassan Abdelhalim, Sören Laue, and 1 more authorarXiv preprint arXiv:2508.13729, May 2025Understanding what knowledge is implicitly encoded in deep learning models is essential for improving the interpretability of AI systems. This paper examines common methods to explain the knowledge encoded in word embeddings, which are core elements of large language models (LLMs). These methods typically involve mapping embeddings onto collections of human-interpretable semantic features, known as feature norms. Prior work assumes that accurately predicting these semantic features from the word embeddings implies that the embeddings contain the corresponding knowledge. We challenge this assumption by demonstrating that prediction accuracy alone does not reliably indicate genuine feature-based interpretability. We show that these methods can successfully predict even random information, concluding that the results are predominantly determined by an algorithmic upper bound rather than meaningful semantic representation in the word embeddings. Consequently, comparisons between datasets based solely on prediction performance do not reliably indicate which dataset is better captured by the word embeddings. Our analysis illustrates that such mappings primarily reflect geometric similarity within vector spaces rather than indicating the genuine emergence of semantic properties.
@article{herasimchyk2025prediction, title = {Prediction is not Explanation: Revisiting the Explanatory Capacity of Mapping Embeddings}, author = {Herasimchyk, Hanna and Abdelhalim, Alhassan and Laue, S{\"o}ren and Regneri, Michaela}, journal = {arXiv preprint arXiv:2508.13729}, year = {2025}, }
2024
- Detecting Conceptual Abstraction in LLMsMichaela Regneri, Alhassan Abdelhalim, and Soeren LaueIn Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), May 2024
We show a novel approach to detecting noun abstraction within a large language model (LLM). Starting from a psychologically motivated set of noun pairs in taxonomic relationships, we instantiate surface patterns indicating hypernymy and analyze the attention matrices produced by BERT. We compare the results to two sets of counterfactuals and show that we can detect hypernymy in the abstraction mechanism, which cannot solely be related to the distributional similarity of noun pairs. Our findings are a first step towards the explainability of conceptual abstraction in LLMs.
@inproceedings{regneri-etal-2024-detecting, title = {Detecting Conceptual Abstraction in {LLM}s}, author = {Regneri, Michaela and Abdelhalim, Alhassan and Laue, Soeren}, editor = {Calzolari, Nicoletta and Kan, Min-Yen and Hoste, Veronique and Lenci, Alessandro and Sakti, Sakriani and Xue, Nianwen}, booktitle = {Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024)}, month = may, year = {2024}, address = {Torino, Italia}, publisher = {ELRA and ICCL}, url = {https://aclanthology.org/2024.lrec-main.420/}, pages = {4697--4704}, }
2020
- Implementation of nature-inspired optimization algorithms in some data mining tasksAM Hemeida, Salem Alkhalaf, A Mady, and 3 more authorsAin Shams Engineering Journal, May 2020
Data mining optimization received much attention in the last decades due to introducing new optimization techniques, which were applied successfully to solve such stochastic mining problems. This paper addresses implementation of evolutionary optimization algorithms (EOAs) for mining two famous data sets in machine learning by implementing four different optimization techniques. The selected data sets used for evaluating the proposed optimization algorithms are Iris dataset and Breast Cancer dataset. In the classification problem of this paper, the neural network (NN) is used with four optimization techniques, which are whale optimization algorithm (WOA), dragonfly algorithm (DA), multiverse optimization (MVA), and grey wolf optimization (GWO). Different control parameters were considered for accurate judgments of the suggested optimization techniques. The comparitive study proves that, the GWO, and MVO provide accurate results over both WO, and DA in terms of convergence, runtime, classification rate, and MSE.
@article{hemeida2020implementation, title = {Implementation of nature-inspired optimization algorithms in some data mining tasks}, author = {Hemeida, AM and Alkhalaf, Salem and Mady, A and Mahmoud, EA and Hussein, ME and Eldin, Ayman M Baha}, journal = {Ain Shams Engineering Journal}, volume = {11}, number = {2}, pages = {309--318}, year = {2020}, publisher = {Elsevier}, }